Paramètres dans les schedules Fabric
Série Data Platform — Les schedules de pipelines Fabric acceptent maintenant des paramètres. Un ajout discret dans les release notes, mais qui règle un problème concret que beaucoup contournaient depuis des mois. Cet article fait le tour de la fonctionnalité : UI, API, Variable Library, et ce qui manque encore.

Dans Fabric, un pipeline est un flux d’automatisation, il ingère des données, les transforme, les déplace. Un schedule est ce qui le fait tourner automatiquement : tous les jours à 6h, toutes les 15 minutes, etc.
Pendant longtemps, si un même pipeline devait tourner à des heures différentes avec des valeurs différentes. Par exemple charger des données client le matin et des données financières le soir, il fallait maintenir plusieurs exemplaires identiques ou bricoler un orchestrateur en amont.
Les paramètres sont maintenant disponibles nativement dans les schedules. La configuration est portée directement par le schedule, sans duplication de pipeline.
Le schedule dans Fabric
Un pipeline Fabric se déclenche de trois façons : à la demande, sur schedule, ou sur événement (via Data Activator). Le schedule se configure depuis l’onglet Home du pipeline : Schedule > Add Schedule.
On définit une fréquence (toutes les N minutes/heures/jours/semaines/mois), une plage de dates, et un fuseau horaire. Jusqu’à 20 schedules distincts peuvent coexister sur un même pipeline, ce qui permet de gérer des cas comme « toutes les heures en journée, une fois la nuit ».
Il n’existe pas de schedule sans date de fin : pour une exécution indéfinie, on utilise une date lointaine (01/01/2099).
Paramètres dans les schedules
Un pipeline peut exposer des paramètres (filtre de date, identifiant client, mode de traitement). Jusqu’ici, ils ne pouvaient pas être définis dans un schedule : : il fallait déclencher le pipeline manuellement ou passer par un pipeline parent pour les injecter.
Désormais, une section Paramètres transmis apparaît dans le schedule avec deux modes :
Valeur directe — valeur statique saisie dans le schedule.
Référence de variable — valeur issue de la Variable Library (VAR_PARAMETERS/ma_variable).
La Variable Library centralise les valeurs à l’échelle du workspace. Fabric ne stocke plus la valeur dans le schedule mais dans un référentiel modifiable sans impact sur le pipeline.
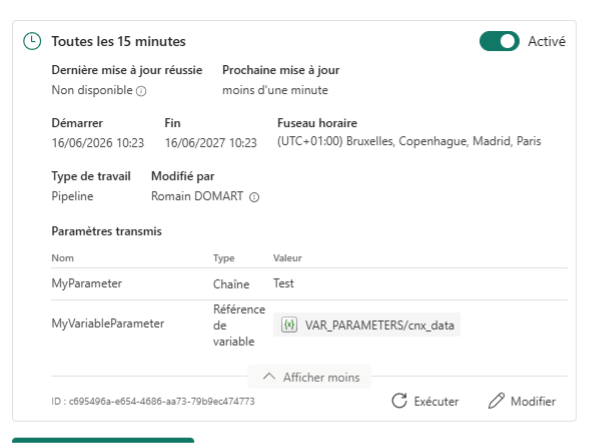
Ainsi, l’intérêt devient clair en multi-environnements : même pipeline, mêmes schedules, mais valeurs contrôlées par environnement. Plus besoin de workspaces entièrement séparés ni de logique de dispatch dans le pipeline.
2 points d’attention :
Le nom du paramètre dans le schedule doit correspondre exactement au nom défini dans le pipeline. Une casse différente, un espace, et le paramètre est silencieusement ignoré à l’exécution (sans message d’erreur).
La sélection du type de paramètre (Chaîne / Référence de variable) peut être capricieuse sur Chrome — le dropdown ne répond pas toujours au premier clic. Si ça coince, essayer Edge ou rafraîchir.
Industrialiser ces schedules : un exemple d’implémentation via API
La configuration manuelle via l’UI fonctionne bien pour quelques pipelines. Sur une plateforme qui en compte plusieurs dizaines, elle devient ingérable : pas de vue d’ensemble, pas de traçabilité, risque d’erreur à chaque modification.
L’API Fabric permet de créer, supprimer et lister les schedules par code. L’idée ici est de disposer d’un notebook dédié, à exécuter à chaque changement, pour déployer l’ensemble des schedules de la plateforme en une seule passe. La configuration est stockée en dehors de Fabric — plus besoin de naviguer dans chaque pipeline pour vérifier ou ajuster un schedule manuellement. On modifie la config, on lance le notebook, c’est déployé.
POST /v1/workspaces/{workspaceId}/items/{pipeline_id}/jobs/Pipeline/schedules
DELETE /v1/workspaces/{workspaceId}/items/{pipeline_id}/jobs/Pipeline/schedules/{id}
GET /v1/workspaces/{workspaceId}/items/{pipeline_id}/jobs/Pipeline/schedules
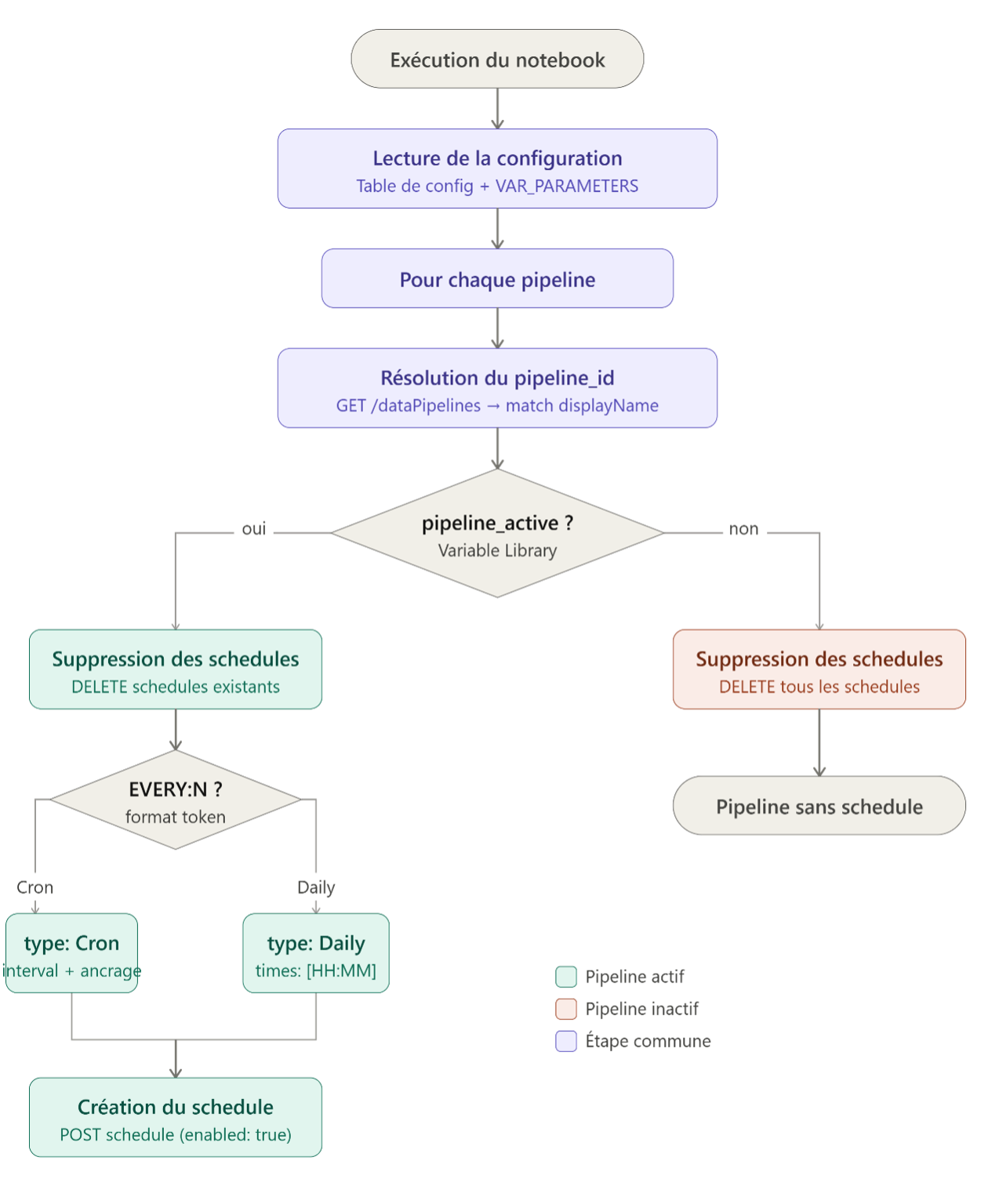
Configuration
La configuration des schedules repose sur deux sources complémentaires.
Une table de configuration stocke le nom du pipeline et son expression de déclenchement. Deux formats sont supportés :
HH:MM:SS → schedule Daily (ex : 06:00:00)
EVERY:N → schedule Cron (ex : EVERY:15, toutes les 15 min depuis maintenant)
EVERY:N@HH:MM → schedule Cron ancré (ex : EVERY:15@06:00, toutes les 15 min depuis 6h)
import re
TIME_PATTERN = re.compile(r"^\d{2}:\d{2}:\d{2}$")
INTERVAL_PATTERN = re.compile(
r"^EVERY:(\d+)(?:@(\d{2}:\d{2}(?::\d{2})?))?$",
re.IGNORECASE
)
La Variable Library (VAR_PARAMETERS) stocke l’état d’activation de chaque pipeline selon l’environnement. Un pipeline peut être actif en production et inactif en recette sans toucher à sa configuration.
env_variables = notebookutils.variableLibrary.getLibrary("VAR_PARAMETERS")
env = env_variables.var_env
# "DEV" / "REC" / "PRD"
schedules_env = env_variables.var_schedules
# liste [{pipeline_name, pipeline_active}]
schedules_env est une liste de dictionnaires portant le nom du pipeline et son flag d’activation pour l’environnement courant.
C’est la seule chose à modifier pour activer ou désactiver un schedule entre environnements.
Traitement par pipeline
Pour chaque pipeline :
1. Résolution du pipeline_id via l’API
2. Récupération des schedules existants
3. Selon le flag pipeline_active de la Variable Library, applique l’une des deux branches
Pipeline actif — recréation du schedule
Les schedules existants sont d’abord supprimés, puis un nouveau est créé. Cette approche évite d’accumuler des schedules redondants et garantit que la configuration reflète exactement ce qui est en base.
La construction du payload dépend du type de déclenchement :
interval_match = INTERVAL_PATTERN.match(str(schedule).strip())
if interval_match:
# EVERY:N ou EVERY:N@HH:MM → type Cron
interval_minutes = int(interval_match.group(1))
start_time = interval_match.group(2)
if start_time:
hh, mm, *ss = (int(x) for x in start_time.split(':'))
start_dt = now.replace(
hour=hh,
minute=mm,
second=ss[0] if ss else 0,
microsecond=0
)
else:
start_dt = now
configuration = {
"type": "Cron",
"startDateTime": start_dt.strftime("%Y-%m-%d %H:%M:%S"),
"endDateTime": "2099-12-31 23:59:59",
"localTimeZoneId": "W. Europe Standard Time",
"interval": interval_minutes
}
else:
# HH:MM:SS → type Daily
configuration = {
"type": "Daily",
"startDateTime": now.strftime("%Y-%m-%d %H:%M:%S"),
"endDateTime": "2099-12-31 23:59:59",
"localTimeZoneId": "W. Europe Standard Time",
"times": [schedule[:5]]
}
payload = {"enabled": True, "configuration": configuration}
requests.post(
schedule_url,
headers=headers,
json=payload
)Pipeline inactif — suppression des schedules
Si pipeline_active est False, le système supprime les schedules sans en créer de nouveaux. Le pipeline reste dans le workspace mais ne s’exécute plus automatiquement.
for s in existing_schedules:
requests.delete(
f"{schedule_url}/{s['id']}",
headers=headers
)📌 Capture — output notebook avec schedule_response.text et le JSON retourné par l’API
Variable Library pour piloter l’activation par environnement
Le flag pipeline_active dans la Variable Library est la seule chose à modifier pour activer ou désactiver un pipeline selon l’environnement. Le notebook et les pipelines restent inchangés.
[
{
"pipeline_name": "PL_LOAD_ENERGIE",
"pipeline_active": true
},
{
"pipeline_name": "PL_EXPORT_REPORTING",
"pipeline_active": false
}
]En recette, pipeline_active est false pour les pipelines critiques. Ils existent, leur configuration est identique à la production, mais aucun schedule ne tourne.
Une réactivation ne nécessite qu’un changement de valeur dans la Variable Library et une réexécution du notebook.
Workflow de modification. Tout ajout ou modification de schedule suit le même processus : mettre à jour la configuration (table de configuration et/ou Variable Library selon ce qui change), puis relancer le notebook au moment de la mise en production.
Le notebook supprime les schedules existants et les recrée à partir de la configuration courante. Il n’y a donc aucun diff à gérer manuellement.
Limite principale : absence des paramètres via API
C’est le point de friction actuel entre les deux approches décrites dans cet article. L’UI permet de configurer des paramètres dans un schedule. L’API, elle, ne les supporte pas encore — ni en écriture, ni en lecture. Un GET sur un schedule configuré avec des paramètres ne les retourne pas dans la réponse. Concrètement, si vous gérez vos schedules via le notebook, vous ne pouvez pas y associer des valeurs de paramètres programmatiquement. Cette partie reste manuelle.

| Situation | Approche |
|---|---|
| Schedules simples, pas d’API | UI seule, profiter des paramètres dès maintenant |
| Orchestration via API, paramètres stables | API pour le schedule + UI pour les paramètres (une fois) |
| Paramètres qui changent selon l’environnement | Variable Library — la valeur est découplée du schedule |
| Paramètres dynamiques complexes | Pipeline orchestrateur en amont ou attendre la mise à jour de l’API |
La fonctionnalité est récente. L’API devrait suivre.
Vous industrialisez déjà des pipelines dans Microsoft Fabric ou vous commencez à structurer vos orchestrations ?
On peut échanger sur vos cas d’usage et vos patterns d’industrialisation.
Article rédigé par Romain Data Engineer Fabric